Iterátory a generátory
Iterátory jsou v Pythonu používané velice často, přestože o tom v mnoha případech ani nevíme nebo nepřemýšlíme. Generátory se staly jedním se základních kamenů pro Python 3.
V této lekci:
- Se dozvíte co jsou iterátory a generátory.
- Naučíte se jak používat
for. - Dozvíte se že kontejnery, které už znáte, jsou iterabilní.
- Pochopítě užitečnost generátorové notace.
Základní použití iterátorů a generátorů¶
Nejprve se podíváme, jak se iterátory v Pythonu používají. Později se dozvíme, jak interně fungují. Jednoduše řečeno, iterátory slouží k postupnému procházení položek v nějakém objektu. Co jsou jednotlivé položky, závisí na daném objektu. Generátor je konkrétním typem iterátoru, který dynamicy vytváří (generuje) položky v závislosti na vnitřním stavu (typicky v závislosti na poslední iteraci). Položky tedy nejsou (resp. nemusí být) uloženy v paměti všechny najednou.
Mnoho objektů v Pythonu je iterabilních (lze z nich vytvořit iterátor), zejména pak
- kontejnery:
list,tuple,dictapod. - řetězce:
str,unicode - objekty typu stream, tedy např.
file
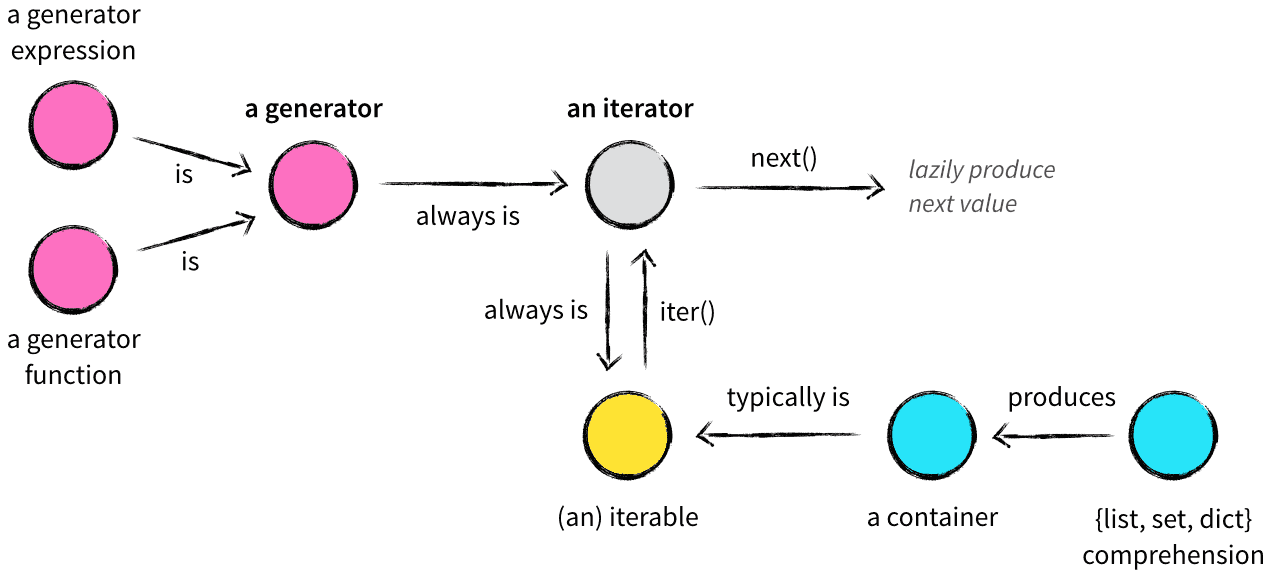
Poměrně přehledně to ukazuje článek Iterables vs. Iterators vs. Generators, ze kterého je i tento názorný obrázek.
from IPython.display import Image
Image(url='http://nvie.com/img/relationships.png', width=700)
for smyčky¶
for funguje v Pythonu výhradně na základě iterátorů. Neexistuje zde "klasická" for smyčka jako počítadlo. Syntaxi si ukážeme na příkladu procházení seznamu.
# vytvoříme nějaký seznam
l = [10, "a", ("x", 1e-3)]
# projdeme položky pomocí for
for x in l:
print(f'x = {x}')
Můžeme také procházet (iterovat) slovník - v takovém případě dostáváme postupně jednotlivé klíče. (Ale pozor: pořadí prvků slovníku je náhodné.)
d = {"one": 1, "two": 2}
for key in d:
print(f'{key} -> {d[key]}')
Pro procházení slovníku se hodí metoda items. Všimněte si použití dvou proměnných (ve skutečnosti to je tuple, jen je zde možná vynechat závorky) pro přiřazení, které slouží k dekompozici, stejně jako např. u volání funkcí.
d = {"one": 1, "two": 2}
for key, value in d.items():
print(f'{key} -> {value}')
Pokud chceme udělat klasické for počítadlo, musíme vytvořit objekt, který bude postupně vracet požadovaná čísla. K tomu slouží funkce range. Použití počítadla by mělo být poslední volbou pro procházení číslovaných polí. Použijeme ho jen v případě, že opravdu potřebujeme čísla jako taková, nikoli pouze prvky nějakého seznamu.
help(range)
range(5)
for x in range(5):
print(x)
Pokud už číslovaní potřebujeme, obvykle potřebujeme také hodnoty s daným indexem. V takovém případě použijeme enumerate:
for i, x in enumerate(('egg', 'bacon', 'sausage', 'spam')):
print(f'{i}. {x}')
Cvičení¶
Pomocí for a enumerate naprogramujte funkci find(where, what), která vrací pole indexů prvků what v iterabilním objektu where. Ověřte pomocí assert testů.
def find(where, what):
???
return indexes
Pokud assert nevyhodí výjimku, funkce je napsaná (velice pravděpodobně) správně.
assert list(find(['FJFI', 2018, 2019], 2018)) == [1]
assert list(find((), 'whatever')) == []
assert list(find('Mississippi', 's')) == [2, 3, 5, 6]
print('Funkce find pracuje správně')
Generátorová notace¶
Pomocí generátorové notace se dají v Pythonu dělat (téměř) zázraky. Používá se pro zkrácený zápis tvorby nového objektu typu list, dict, set nebo generátoru pomocí závorek a klíčových slov for, in, případně if.
Generátorový výraz (Generator expression)¶
Kulaté závorky: (výraz for proměnná in iterable)
(x ** 2 for x in range(1, 11)) # generátor, tj. iterovatelný objekt
Generátory seznamů (List comprehension)¶
Hranaté závorky: [výraz for proměnná in iterable]
[x ** 2 for x in range(1, 11)] # klasický seznam
Toto můžeme použít i na převod generátoru na seznam.
# vytvoříme generátor
gen = (x ** 2 for x in range(1, 11))
# a teprve z něj vytvoříme list
[x for x in gen]
Generátory množin (Set comprehension)¶
Složené závorky: {výraz for proměnná in iterable}
jmena = ["Ester", "Eva", "Egon", "Marie", "Monika", "Richard"]
prvni_pismena = {jmeno[0] for jmeno in jmena}
print(f"Množina počátečních písmen jmen (každé jen jednou):\n{prvni_pismena}")
Generátory slovníků (Dictionary comprehension)¶
(Podporováno od Pythonu 2.7.)
Složené závorky: {klíč: hodnota for proměnná in iterable}. Od generátoru množit se liší přítomností dvojtečky ve výrazu klíč: hodnota.
jmena = ["Ester", "Eva", "Egon", "Marie", "Monika", "Richard"]
# Slovník s délkami jmen
{jmeno : len(jmeno) for jmeno in jmena}
Filtrování pomocí if¶
U generátorové notace můžeme použít if jako filtr. Jako příklad vybereme z mocnin dvou jen ty dvouciferné.
# vytvoříme generátor (horní mez jsme nějak odhadli)
gen = (2 ** n for n in range(1, 11))
[x for x in gen if 9 < x < 100]
Vícenásobné for¶
V jednom generátorovém výrazu můžeme mít více for klíčových slov. Bude se pak iterovat postupně přes všechny prvky všech iterárátorů za for. Je to ekvivalentní vnořenému for cyklu.
# vytvoření dvojic ze dvou množin
m1 = {"a", "b", "c"}
m2 = {"a", "c", "e"}
{(x1, x2) for x1 in m1 for x2 in m2}
Cvičení¶
Přepište funkci find pomocí jednoho genráorového výrazu.
# vytvoříme seznamy a generátor
l1 = range(1,9)
l2 = (2 ** n for n in l1)
# nyní je chceme procházet současně
for x, y in zip(l1, l2):
print(f"{x} -> {y}")
enumerate¶
Pokud potřebujeme znát číselný index prvku, je lepší použít enumerate, která postupně vrací (index, prvek).
for i, n in enumerate("ABCDE"):
print(f"{i} -> {n}")
dict.items¶
Některé třídy mají pomocné metody pro iterace. Např. dict.items vrací dvojice (klíč, hodnota).
# slovník s částí ascii tabulky
d = {i: chr(i) for i in range(40, 50)}
for k, v in d.items():
print(f"{k} -> {v}")
modul itertools¶
Tento modul obsahuje mnoho zajímavých a užitečných funkcí pro tvorbu iterátorů, často inspirovných funkcionálními jazyky (o funkcionálním programování v Pythonu ještě uslyšíme).
# vypíšeme si funkce v itertools
import itertools
sorted([f for f in itertools.__dict__ if not f.startswith("_")])
V dokumentaci naleznete také recepty, jak vytvořit další užitečné funkce pomocí itertools. Ukažme si například, jak získat n-tý prvek z iterátoru (který pochopitelně nemusí mít číselné indexování).
from itertools import islice
# definice funkce
def nth(iterable, n, default=None):
"Returns the nth item or a default value"
# všimněte si použití funkce next
return next(islice(iterable, n, None), default)
# jednoduché použití
print(nth(range(100), 3))
Cvičení¶
- Pro slovníkovou reprezentaci polynomů implementujte funkci pro násobení polynomů
polydot(polynom1, polynom2). Slovníková reprezentace polynomu má jako klíče exponenty a jako hodnoty koeficienty u daných polynomů. Např. reprezentace $x^3 - 2x + 1$ je{3: 1, 1:-2, 0: 1}. Využijtedictmetodugetnebocollections.defaultdict. - Naprogramujte ekvivalent funkce enumerate pomocí funkce zip (případně itertools.izip) a vhodné funkce z modulu
itertools, která bude sloužit jako počítadlo. Aplikujte na libovolně vytvořený seznam jmen a vytvořte slovník, který přiřazuje pořadová čísla.
# Test pro cvičení 1
poly1 = {3: 1, 1: -2, 0: 1}
poly2 = {1: -1, 0: 2}
assert polydot(poly1, poly2) == {4: -1, 3: 2, 2: 2, 1: -5, 0: 2}
print('Funkce polydot pracuje správně')
Architektura iterátorů¶
Účelem iterátorů je postupně procházet (iterovat) prvky objektu. To, jakým způsobem jsou chápány a implementovány prvky je specifické pro daný objekt. Klíčem k pochopení iterátorů jsou dvě speciálně pojmenované metody __iter__ a __next__ (next v Pythonu 2). Ty se obvykle nevolají přímo, ale např. pomocí for cyklu nebo generátorové notace. Ukažme si to na příkladu jednoduchého počítadla.
class Counter(object):
"""Primitivní počítadlo"""
def __init__(self, n):
self.n = n
def __iter__(self):
self.i = 0
return self
def __next__(self):
i = self.i
self.i += 1
if self.i > self.n:
raise StopIteration
return i
# použijeme iterátor Counter ve for smyčce
my_counter = Counter(4)
for a in my_counter:
print(a)
# vytvoříme list pomocí generátorové notace
print([a for a in my_counter])
Jak to celé funguje? Pomocí iterátorového protokolu, který si můžeme ukázat krok za krokem. Jako první se vytvoří objekt pomocí metody __iter__ (ta se zavolá při for cyklu i generátorové notaci)
# iter zavolá __iter__
it = iter(Counter(5))
print(it)
print(dir(it))
Poté se volá metoda next (resp. __next__ v Python 3). Obojí je možné volat pomocí vestavěné funkce next:
print(next(it))
print(next(it))
Iterace končí vyhozením výjimky StopIteration. Funguje to tedy asi takto:
it = iter(Counter(4))
while True:
try:
print(next(it))
except StopIteration:
break
No a teď už konečně víme, jak funguje "klasický" for cyklus s počítáním pomocí funkce range, resp. xrange. (V Pythonu 2 vrací range list a xrange generátor. V Pythonu 3 existuje už jen range, který vrací generátor.)
for i in range(4):
print(i)
V Pythonu jsou iterace základním (a vlastně jediným) mechanismem for smyček. Pokud chceme provést nějakou operaci na množině objektů, která je typicky uložena v nějakém kontejneru (list, tuple, dic, set spod.), použijeme k tomu iterace. Ukážeme si několik příkladů.
Architektura generátorů¶
Pro vytvoření generátoru, nebo lépe řečené generátorové funkce, služí klíčové slovo yield. Jakmile se při běhu funkce narazí na klíčové slovo yield, funkce se "zmrazí" (zachová se interní stav pomocí uzávěru nebo closure -- o tom si ještě povíme) a vrátí se výraz za yield. Spuštění generátorová funkce jako takové pak vrací iterátor, který řídí spouštění této funkce. Ukážeme si jednoduchý příklad, který počítá donekonečna.
def countup(value=0):
print("Příkazy se spustí až po zavolání prvního next")
while True:
yield value
value += 1
g = countup(2)
next(g)
next(g)
next(g)
Takto bychom mohli pokračovat donekonečna. Pokud chceme, aby iterátor někde zastavil, musíme použít vyjímku.
def countupto(to_value, from_value=0):
value = from_value
while value < to_value:
yield value
value += 1
# tuto výjimky můžeme vyhodit manuálně, v tomto případě to ale není nutné
# raise StopIteration
g = countupto(2)
next(g)
next(g)
next(g)
Výjimka StopIteration je odchycena ve for cyklech, generátorech seznamů apod. Můžeme tedy udělat např. toto:
[i for i in countupto(10, 1)]
Pokud toto zkusíte s countup, iterace nikdy neskončí, resp. skončí nějakou chybou nebo přehřátím počítače.
Ukázali jsme si základní tvorbu generátorů. Celý protokol je ale bohatší a umožňuje komunikovat s generátorovou funkcí pomocí posílání hodnot nebo výjimek, viz dokumentace.
Cvičení¶
- Vytvořte generátorovou funkci pro čísla, která jsou definována rekurentním vztahem $$F_{n}=F_{n-1}+F_{n-2},\ F_0 = 0,\ F_1 = 1$$
Komentáře
Comments powered by Disqus